MapReduce
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters(thousands of nodes) of commodity hardware in a reliable,fault-tolerant manner – The Apache Software Foundation
- MapReduce distributes the processing of data on the cluster.
- MapReduce works by breaking the processing into two phases: the map phase (transforming) and the reduce phase (aggregating).
- Each phase has key-value pairs as input and output, the types of which may be chosen by the programmer.
Key-Value Pairs
Input, output, and intermediate records in MapReduce are represented in the form of key-value pairs.
The key is an identifier; for instance, the name of the attribute. In MapReduce programming in Hadoop, the key is not required to be unique.
The value is the data that corresponds to the key. This value can be a simple, scalar value such as an integer, or a complex object such as a list of other objects.
Complex problems in Hadoop are often decompose into a series of operations against key-value pairs.

Map phase
The Map phase is the initial phase of processing in which we will use an input dataset as a data source for processing.
The Map phase uses input format and record reader functions in its specific implementation to derive records in the form of key-value pairs for the input data.
The Map phase then applies one or several functions to each key-value pair over a portion of the dataset.
Reduce phase
Each Reduce task (or Reducer) executes a reduce() function for each intermediate key and its list of associated intermediate values.
The output from each reduce() function is zero or more key-value pairs considered to be part of the final output.
This output may be the input to another Map phase in a complex multistage computational workflow.
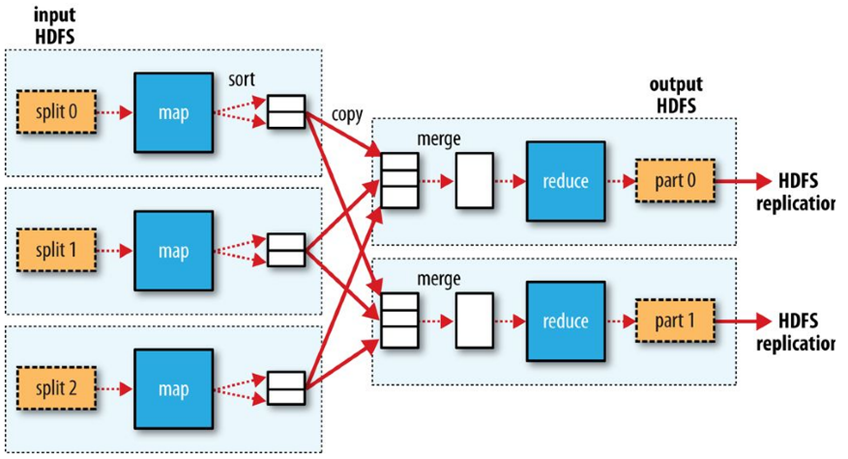
Shuffle and Sort
Between the Map phase and the Reduce phase, there is the Shuffle and Sort phase.
Intermediate data from completed Map tasks (keys and lists of values) is sent to the appropriate Reducer, depending upon the partitioning function specified.
The keys and their lists of values are then merged into one list of keys and their associated values per Reducer, with the keys stored in key-sorted order according the key datatype.
The Shuffle-and-Sort phase is the entire process of transferring intermediate data from Mappers to Reducers and merging the lists of key-value pairs into lists in key-sorted order on each Reducer.
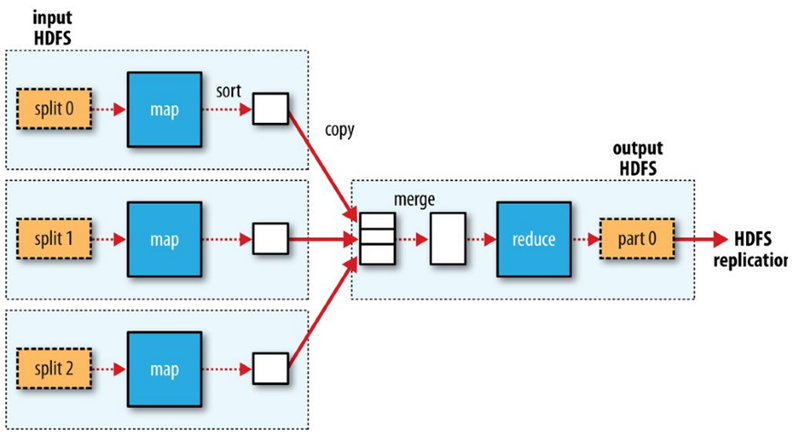
Reduce Tasks
Reduce tasks don’t have the advantage of data locality.The input to a single reduce task is normally the output from all mappers.
The sorted map outputs have to be transferred across the network to the node where the reduce task is running, where they are merged and then passed to the user-defined reduce function.
The output of the reduce is normally stored in HDFS for reliability.
For each HDFS block of the reduce output, the first replica is stored on the local node, with other replicas being stored on off-rack nodes for reliability (remember HDFS block replication).
Writing the reduce output does consume network bandwidth, but only as much as a normal HDFS write pipeline consumes.
Data flow with a single reduce task
When there are multiple reducers, the map tasks partition their output, each creating one partition for each reduce task.
There can be many keys (and their associated values) in each partition, but the records for any given key are all in a single partition.
The partitioning can be controlled by a user-defined partitioning function.
Each reduce task is fed by many map tasks (“Shuffle” from the “Shuffle and Sort”).
Data flow with multiple reduce tasks