Cassandra
Another notable project emanating from the Bigtable paper is Apache Cassandra.
Cassandra was initially developed at Facebook and later released as an open source project under the Apache software licensing scheme in 2008.
Cassandra became a top-level Apache project in 2010.
Apache Cassandra is an open source, distributed, decentralized, elastically scalable, highly available, fault-tolerant, tuneably consistent, row-oriented database that bases its distribution design on Amazon’s Dynamo and its data model on Google’s Bigtable. Created at Facebook, it is now used at some of the most popular sites on the Web.
Distributed and Decentralized
Cassandra is distributed, which means that it is capable of running on multiple machines while appearing to users as a unified whole.
Cassandra is decentralized, meaning that every node is identical; no Cassandra node performs certain organizing operations distinct from any other node.
The fact that Cassandra is decentralized means that there is no single point of failure.
All of the nodes in a Cassandra cluster function exactly the same as opposed to the master/slave relationship in HBase for example.
Elastic Scalability
Scalability is an architectural feature of a system that can continue serving a greater number of requests with little degradation in performance.
- Vertical scaling — simply adding more hardware capacity and memory to your existing machine — is the easiest way to achieve this.
- Horizontal scaling means adding more machines that have all or some of the data on them so that no one machine has to bear the entire burden of serving requests.
Elastic scalability refers to a special property of horizontal scalability. It means that your cluster can seamlessly scale up and scale back down.
Cassandra allows to easily add or remove machines or nodes as needed.
Tuneable Consistency
Consistency essentially means that a read always returns the most recently written value.
Cassandra trades some consistency in order to achieve total availability.
Cassandra is frequently called “eventually consistent”, which is a bit misleading.
Eventual consistency means on the surface that all updates will propagate throughout all of the replicas in a distributed system, but that this may take some time. Eventually, all replicas will be consistent.
Cassandra is more accurately termed “tuneably consistent”, which means it allows you to easily decide the level of consistency you require, in balance with the level of availability.
Tuneably consistency is achieved by controlling the number of replicas to block on for all updates.
This is done by setting the consistency level against the replication factor.
- The replication factor lets you decide how much you want to pay in performance to gain more consistency. You set the replication factor to the number of nodes in the cluster you want the updates to propagate to.
- The consistency level is a setting that clients must specify on every operation and that allows you to decide how many replicas in the cluster must acknowledge a write operation or respond to a read operation in order to be considered successful.
If the consistency level = replication factor -> we gain stronger consistency. At the cost of synchronous blocking operations that wait for all nodes to be updated and declare success before returning (impacts availability).
If consistency level < replication factor -> the update is considered successful even if some nodes are down.
Row-Oriented
Cassandra’s data model can be described as a partitioned row store, in which data is stored in sparse multidimensional hashtables. Cassandra has frequently been referred to as a “column-oriented” database. But Cassandra’s data store is not organized primarily around columns.
“Sparse” means that for any given row we can have one or more columns, but each row doesn’t need to have all the same columns as other rows like it (as in a relational model).
“Partitioned” means that each row has a unique key which makes its data accessible, and the keys are used to distribute the rows across multiple data stores.
Cassandra Data Model
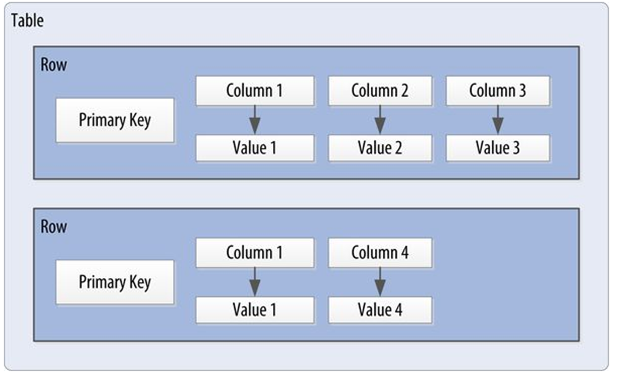
Cassandra uses a unique identifier/primary key for each row. Rows can be seen as a group of columns that should be treated together as a set.
We don’t need to store a value for every column every time we store a new entity. We have a sparse, multidimensional array structure.
Rows can be wide or skinny, depending on the number of columns the row contains.
A wide row is a row that has lots (perhaps tens of thousands or even millions) of columns. Typically there is a smaller number of rows that go along with so many columns.
Conversely, we can have a smaller number of columns and use many different rows, closer to the relational model. That’s the skinny model (as seen on the previous slide).
Wide Rows
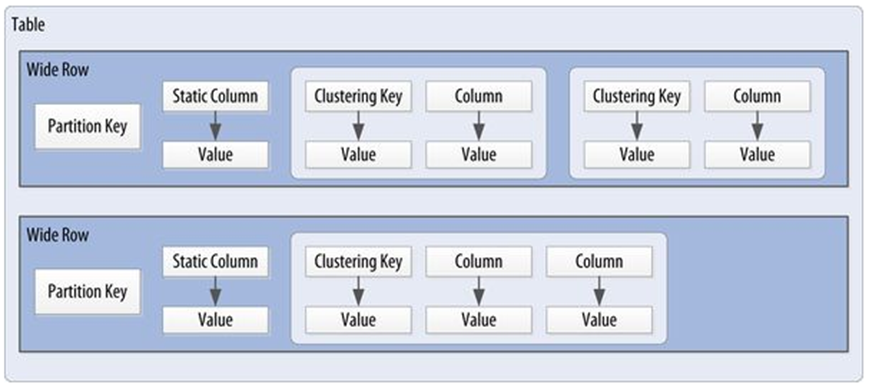
Cassandra uses a special primary key called a composite key (or compound key) to represent wide rows, also called partitions.
The composite key consists of a partition key, plus an optional set of clustering columns.
The partition key is used to determine the nodes on which rows are stored.
The clustering columns are used to control how data is sorted for storage within a partition.
Cassandra also supports an additional construct called a static column, which is for storing data that is not part of the primary key but is shared by every row in a partition.
Gossip protocol
To support decentralization and partition tolerance, Cassandra uses a gossip protocol that allows each node to keep track of state information about the other nodes in the cluster.
The gossiper runs every second on a timer.
Gossip protocols
- generally assume a faulty network.
- are commonly employed in very large, decentralized network systems.
- are often used as an automatic mechanism for replication in distributed databases.
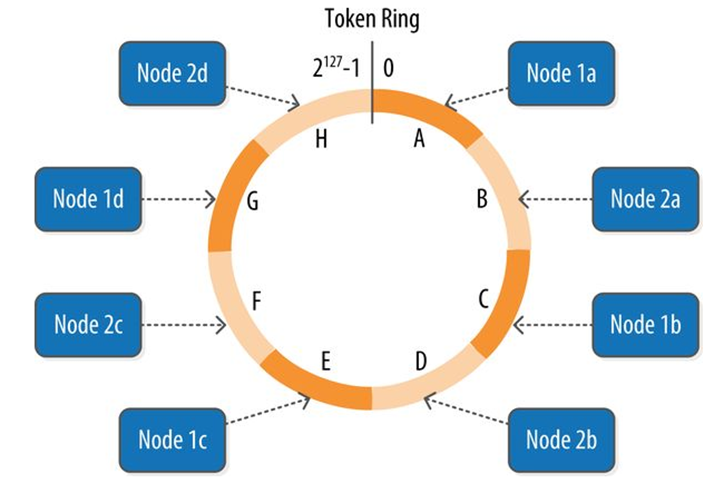
Rings and Tokens
Cassandra keeps track of the physical layout of nodes in a cluster.
Cassandra represents the data managed by a cluster as a ring.
Each node in the ring is assigned one or more ranges of data described by a token, which determines its position in the ring.
A token is a 64-bit integer ID used to identify each partition.
Data is assigned to nodes by using a hash function to calculate a token for the partition key.
The partition key token is compared to the token values for the various nodes to identify the range, and therefore the node, that owns the data.