HBase
HBase is a distributed column-oriented database built on top of HDFS.
HBase is the Hadoop application (amongst other) to use when we require real-time read/write random access to very large datasets.
HBase is able to do what an RDBMS cannot: host very large, sparsely populated tables on clusters made from commodity hardware.
HBase is not relational and does not support SQL, but it has an API to perform CRUD operations (Create, Read, Update, Delete).
HBase project was started toward the end of 2006 and was modeled after Google’s Bigtable paper, which had just been published.
The first HBase release was bundled as part of Hadoop 0.15.0 in October 2007. In May 2010, HBase graduated from a Hadoop subproject to become an Apache Top Level Project.
Today, HBase is a mature technology used in production across a wide range of industries.
HBase Data Model
HBase stores data as a sparse, multidimensional, sorted map.
The map is indexed by its key (the row key), and values are stored in cells (consisting of a column key and column value). The row key and column keys are strings and the column value is an uninterpreted byte array (which could represent any primitive or complex datatype).
HBase is multidimensional, as each cell is versioned with a time stamp.
Row columns are grouped into column families. At table design time, one or more column families is defined. Column families will be used as physical storage groups for columns. Different column families may have different physical storage characteristics such as block size, compression settings, or the number of cell versions to retain.
A table’s column families must be specified up front as part of the table schema definition, but new column family members can be added on demand.
Physically, all column family members are stored together on the file system. We can say HBase is a column-family-oriented store.
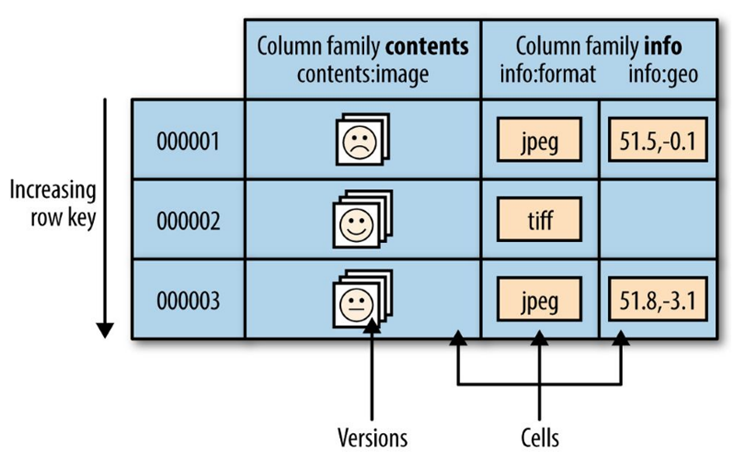
- info:format and info:geo are both members of the info column family
- contents:image belongs to the contents family.
- A new column info:camera can be offered by a client as part of an update
Regions
Tables are automatically partitioned horizontally by HBase into regions. Each region comprises a subset of a table’s rows, usually a range of sorted row keys.
Initially, a table comprises a single region, but as the region grows it eventually crosses a configurable size threshold, at which point it splits at a row boundary into two new regions of approximately equal size. Until this first split happens, all loading will be against the single server hosting the original region.
Regions are the units that get distributed over an HBase cluster.
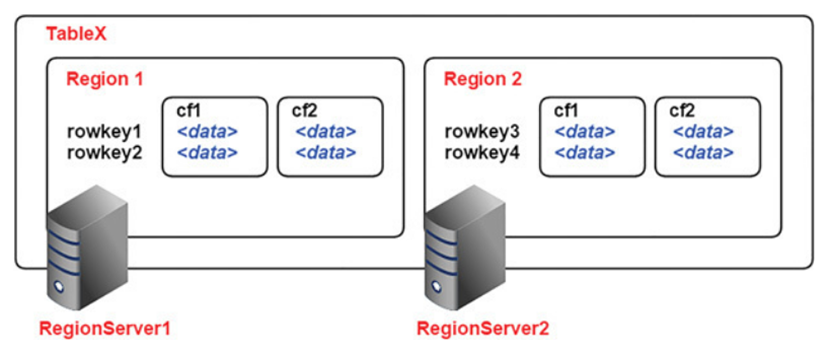
Like HDFS is built of clients, workers, and a coordinating master, the namenode and datanodes, HBase is made up of an HBase master node orchestrating a cluster of one or more regionserver workers.
The HBase master is responsible for assigning regions to registered regionservers, and for recovering regionserver failures.
The regionservers manage region splits, informing the HBase master about the new daughter regions so it can manage the offlining of parent regions and assignment.