Demo Spark
SparkContext
In order to use Spark and its API we will need to use a SparkContext. When running Spark, you start a new Spark application by creating a SparkContext (http://spark.apache.org/docs/latest/api/python/pyspark.html#pyspark.SparkContext).
When using Databricks, the SparkContext is created for you automatically as sc.
sc
Historically, Apache Spark has had two core contexts that are available to the user. The sparkContext and the SQLContext made available as sqlContext, these contexts make a variety of functions and information available to the user. The sqlContext makes a lot of DataFrame functionality available while the sparkContext focuses more on the Apache Spark engine itself.
print(sqlContext)
print(sc)
In Apache Spark 2.X, there is a new context - the SparkSession (https://spark.apache.org/docs/latest/api/python/pyspark.sql.html?highlight=udf#pyspark.sql.SparkSession).
We can access it via the spark variable. As Dataset and Dataframe API are becoming new standard, SparkSession is the new entry point for them.
# If you're on 2.X the spark session is made available with the variable below
spark
sparkContext is still used as the main entry point for RDD API and is available under sc or spark.sparkContext.
print(spark.sparkContext)
print(sc)
Transformations and Actions
Spark allows two distinct kinds of operations by the user. There are transformations and there are actions.
Transformations
Transformations are operations that will not be completed at the time you write and execute the code in a cell - they will only get executed once you have called an action. An example of a transformation might be to convert an integer into a float or to filter a set of values.
Actions
Actions are commands that are computed by Spark right at the time of their execution. They consist of running all of the previous transformations in order to get back an actual result. An action is composed of one or more jobs which consists of tasks that will be executed by the workers in parallel where possible.
# An example of RDD created from a list
numList = [1,2,3,4,5]
firstRDD = sc.parallelize(numList)
# An example of a transformation
# Multiply the values by 2
secondRDD = firstRDD.map(lambda x: x*2)
# An example of an action
secondRDD.collect()
It gives a simple way to optimize the entire pipeline of computations as opposed to the individual pieces. This makes it exceptionally fast for certain types of computation because it can perform all relevant computations at once. Technically speaking, Spark pipelines this computation which we can see in the image below. This means that certain computations can all be performed at once (like a map and a filter) rather than having to do one operation for all pieces of data and then the following operation.
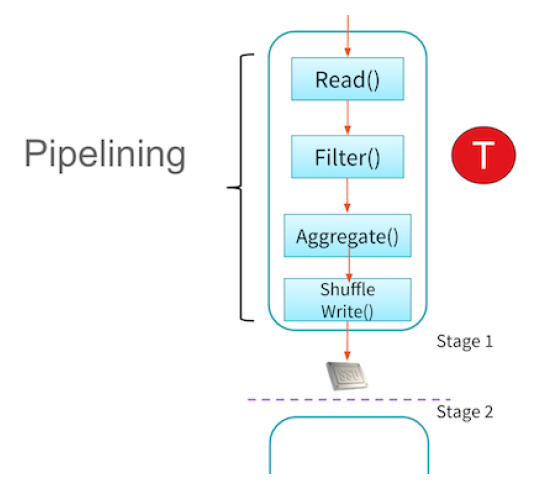
Transformations are lazy in order to build up the
entire flow of data from start to finish required by the user. Any calculation can be recomputed from the very
source data allowing Apache Spark to handle any failures that occur along the way,
and successfully handle stragglers. With each transformation Apache Spark creates a plan for how it will
perform this work.
To get a sense for what this plan consists of, run the following code in a cell (we will explain this code later):
wordsList = ['cat', 'elephant', 'rat', 'rat', 'cat']
wordsRDD = sc.parallelize(wordsList)
wordCountsCollected = (wordsRDD
.map(lambda x: (x,1))
.reduceByKey(lambda a,b: a+b)
.collect())
Click the little arrow next to where it says (1) Spark Jobs after that cell finishes executing and then click the View link. This brings up the Apache Spark Web UI right inside of your notebook. This can also be accessed from the cluster attach button at the top of this notebook. In the Spark UI, you should see something that includes a diagram similar to this:
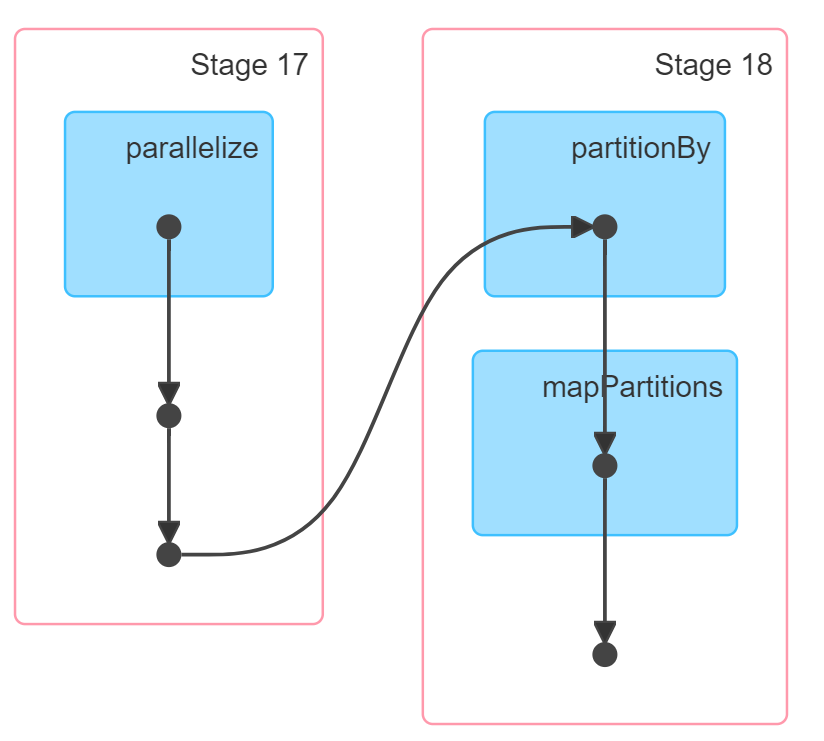 This is a Directed Acyclic Graphs (DAG)s of all the computations that have to be performed in order to get to that result. Again, this DAG is generated because transformations are lazy - while generating this series of steps Spark will optimize lots of things along the way and will even generate code to do so.
This is a Directed Acyclic Graphs (DAG)s of all the computations that have to be performed in order to get to that result. Again, this DAG is generated because transformations are lazy - while generating this series of steps Spark will optimize lots of things along the way and will even generate code to do so.
Spark example with a Word count application
In this example, we will develop a simple word count application. we will write code that calculates the most common words in the Complete Works of William Shakespeare (http://www.gutenberg.org/ebooks/100) retrieved from Project Gutenberg (http://www.gutenberg.org/wiki/Main_Page).
In Databricks, create a new Notebook and follow the steps below.
I. Creating a base RDD and pair RDDs
Create a base RDD
There are two ways to create RDDs:_parallelizing_an existing collection in your driver program, or referencing a dataset in an external storage system, such as a shared filesystem, HDFS, HBase, or any data source offering a Hadoop InputFormat.
Parallelized collections are created by calling SparkContext’s parallelize method. The elements of the collection are copied to form a distributed dataset that can be operated on in parallel. One important parameter for parallel collections is the number of partitions to cut the dataset into. Spark will run one task for each partition of the cluster. Typically you want 2-4 partitions for each CPU in your cluster. Normally, Spark tries to set the number of partitions automatically based on your cluster. However, you can also set it manually by passing it as a second parameter.
We will start by generating a base RDD by using a Python list and the sc.parallelize method. Then we'll print out the type of the base RDD.
Enter the following code in a cell:
wordsList = ['cat', 'elephant', 'rat', 'rat', 'cat']
wordsRDD = sc.parallelize(wordsList, 4)
# Print out the type of wordsRDD
print type(wordsRDD)
wordsRDD.collect()
Pluralize and test
Let's use a _map() _transformation with a lambda function to add the letter 's' to each string in the base RDD we just created:
pluralLambdaRDD = wordsRDD.map(lambda x: x + 's')
print(pluralLambdaRDD.collect())
Now let's use map() and a lambda function to return the number of characters in each word. We will collect this result directly into a variable.
pluralLengths = (pluralRDD
.map(lambda x: len(x))
.collect())
print(pluralLengths)
Pair RDDs
The next step in writing our word counting program is to create a new type of RDD, called a pair RDD. A pair RDD is an RDD where each element is a pair tuple (k, v) where k is the key and v is the value. In this example, we will create a pair consisting of ('<word>', 1) for each word element in the RDD. We can create the pair RDD using the map() transformation with a lambda() function to create a new RDD.
print(wordsRDD.collect())
wordPairs = wordsRDD.map(lambda x: (x,1))
print(wordPairs.collect())
II. Counting with pair RDDs
Now, let's count the number of times a particular word appears in the RDD. There are multiple ways to perform the counting, but some are much less efficient than others. A naive approach would be to collect() all of the elements and count them in the driver program. While this approach could work for small datasets, we want an approach that will work for any size dataset including terabyte- or petabyte-sized datasets. In addition, performing all of the work in the driver program is slower than performing it in parallel in the workers. For these reasons, we will use data parallel operations.
Use groupByKey() approach
An approach you might first consider (we'll see shortly that there are better ways) is based on using the groupByKey()
(http://spark.apache.org/docs/latest/api/python/pyspark.html#pyspark.RDD.groupByKey) transformation. As the name implies, the groupByKey() transformation groups all the elements of the RDD with the same key into a single list in one of the partitions.
There are two problems with using groupByKey():
- The operation requires a lot of data movement to move all the values into the appropriate partitions.
- The lists can be very large. Consider a word count of English Wikipedia: the lists for common words (e.g., the, a, etc.) would be huge and could exhaust the available memory in a worker.
Use groupByKey() to generate a pair RDD of type ('word', iterator) .
print(wordPairs.collect())
wordsGrouped = wordPairs.groupByKey().mapValues(lambda x: list(x))
#wordsGrouped = wordPairs.groupByKey().map(lambda (x,y): (x,list(y)))
for key, value in wordsGrouped.collect():
print('{0}: {1}'.format(key, value))
Using the groupByKey() transformation creates an RDD containing 3 elements, each of which is a pair of a word and a Python iterator.
mapValues pass each value in the key-value pair RDD through a map function without changing the keys. In this case the map changes the iterator to a list of values. mapValues is only applicable for PairRDDs.
Now sum the iterator using a map() transformation. The result should be a pair RDD consisting of (word, count) pairs.
print(wordsGrouped.collect())
wordCountsGrouped = wordsGrouped.map(lambda (k,v): (k,sum(v)))
#wordCountsGrouped = wordsGrouped.mapValues(lambda v: sum(v))
print(wordCountsGrouped.collect())
NOTE:lambda (k,v):does not work in Python 3.
Use reduceByKey approach
A better approach is to start from the pair RDD and then use the reduceByKey()(http://spark.apache.org/docs/latest/api/python/pyspark.html#pyspark.RDD.reduceByKey) transformation to create a new pair RDD. The reduceByKey() transformation gathers together pairs that have the same key and applies the function provided to two values at a time, iteratively reducing all of the values to a single value. reduceByKey() operates by applying the function first within each partition on a per-key basis and then across the partitions, allowing it to scale efficiently to large datasets.
print(wordPairs.collect())
wordCounts = wordPairs.reduceByKey(lambda a,b: a+b)
print(wordCounts.collect())
The expert version of the code performs the map() to pair RDD, reduceByKey() transformation, and collect in one statement.
print(wordsRDD.collect())
wordCountsCollected = (wordsRDD
.map(lambda x: (x,1))
.reduceByKey(lambda a,b: a+b)
.collect())
print(wordCountsCollected)
III. Apply word count to a file
Let's finish developing our word count application. We will have to build the wordCount function, deal with real world problems like capitalization and punctuation, load in our data source, and compute the word count on the new data.
wordcount function
First, let's define a function for word counting. We will reuse the techniques that we saw earlier. This function should take in an RDD that is a list of words like wordsRDD and return a pair RDD that has all of the words and their associated counts.
def wordCount(wordListRDD):
"""Creates a pair RDD with word counts from an RDD of words.
Args:
wordListRDD (RDD of str): An RDD consisting of words.
Returns:
RDD of (str, int): An RDD consisting of (word, count) tuples.
"""
wordListCount = (wordListRDD.map(lambda x: (x,1))
.reduceByKey(lambda a,b: a+b))
return wordListCount
Capitalization and punctuation
Real world files are more complicated than the data we have been using so far.
Some of the issues we have to address are:
- Words should be counted independent of their capitialization (e.g., Spark and spark should be counted as the same word).
- All punctuation should be removed.
- Any leading or trailing spaces on a line should be removed.
We will now define the function removePunctuation that converts all text to lower case, removes any punctuation, and removes leading and trailing spaces. We will use the Python re (https://docs.python.org/2/library/re.html) module to remove any text that is not a letter, number, or space.
More on regular expressions here: https://developers.google.com/edu/python/regular-expressions
import re
def removePunctuation(text):
"""Removes punctuation, changes to lower case, and strips leading and trailing spaces.
Note:
Only spaces, letters, and numbers should be retained. Other characters should should be eliminated
(e.g. it's becomes its).
Leading and trailing spaces should be removed after punctuation is removed.
Args:
text (str): A string.
Returns:
str: The cleaned up string.
"""
return re.sub(r'[^A-Za-z0-9 ]', '', text).lower().strip()
print removePunctuation('Hi, you!')
print removePunctuation(' No under_score!')
print removePunctuation(' * Remove punctuation then spaces * ')
Load a text file
We will use the Complete Works of William Shakespeare (http://www.gutenberg.org/ebooks/100) from Project Gutenberg (http://www.gutenberg.org/wiki/Main_Page).
To convert a text file into an RDD, we use the SparkContext.textFile() method. We also apply the recently defined removePunctuation() function using a map() transformation to strip out the punctuation and change all text to lower case. Since the file is large we use take(15) , so that we only print 15 lines.
NOTE: the file has already been uploaded in Databricks FS for us.
import os.path
baseDir = os.path.join('databricks-datasets')
inputPath = os.path.join('cs100', 'lab1', 'data-001', 'shakespeare.txt')
fileName = os.path.join(baseDir, inputPath)
shakespeareRDD = (sc.textFile(fileName, 8).map(removePunctuation))
print '\n'
.join(shakespeareRDD
.zipWithIndex() # to (line, lineNum)
.map(lambda (l, num): '{0}: {1}'.format(num, l)) # to 'lineNum: line'
.take(15))
Words from lines
Before we can use the wordcount() function, we have to address two issues with the format of the RDD:
- The first issue is that that we need to split each line by its spaces.
- The second issue is we need to filter out empty lines.
To solve the first issue, we will apply, for each element of the RDD, Python's string split()(https://docs.python.org/2/library/string.html#string.split) function.
We also would like the newly created RDD to consist of the elements outputted by the function. Simply applying a map() transformation would yield a new RDD made up of iterators. Each iterator could have zero or more elements. Instead, we often want an RDD consisting of the values contained in those iterators. The solution is to use a flatMap()(http://spark.apache.org/docs/latest/api/python/pyspark.html#pyspark.RDD.flatMap) transformation, flatMap() is similar to map(), except that with flatMap() each input item can be mapped to zero or more output elements.
Look at the difference between map() and flatMap() by running this code:
# Let's create a new base RDD to work from
wordsList = ['cat', 'elephant', 'rat', 'rat', 'cat']
wordsRDD = sc.parallelize(wordsList, 4)
# Use map
singularAndPluralWordsRDDMap = wordsRDD.map(lambda x: (x, x + 's'))
# Use flatMap
singularAndPluralWordsRDD = wordsRDD.flatMap(lambda x: (x, x + 's'))
# View the results
print singularAndPluralWordsRDDMap.collect()
print singularAndPluralWordsRDD.collect()
# View the number of elements in the RDD
print singularAndPluralWordsRDDMap.count()
print singularAndPluralWordsRDD.count()
Hence our code for our word count application should be:
shakespeareWordsRDD = shakespeareRDD.flatMap(lambda x: x.split(' '))
shakespeareWordCount = shakespeareWordsRDD.count()
print shakespeareWordsRDD.top(5)
print shakespeareWordCount
Remove empty lines
The next step is to filter out the empty elements using the filter() function:
shakeWordsRDD = shakespeareWordsRDD.filter(lambda x: x <> '')
shakeWordCount = shakeWordsRDD.count()
print shakeWordCount
Count the words
We now have an RDD that is only words. Next, let's apply the wordCount() function to produce a list of word counts. We can view the top 15 words by using the takeOrdered() action; however, since the elements of the RDD are pairs, we need a custom sort function that sorts using the value part of the pair.
top15WordsAndCounts = wordCount(shakeWordsRDD).takeOrdered(15, lambda (w,c): - c)
print '\n'.join(map(lambda (w, c): '{0}: {1}'.format(w, c), top15WordsAndCounts))