Introduction to Data Engineering
What is a Data Engineer?
A data engineer is a worker whose primary job responsibilities involve preparing data for analytical or operational uses. The specific tasks handled by data engineers can vary from organization to organization but typically include building data pipelines to pull together information from different source systems; integrating, consolidating and cleansing data; and structuring it for use in individual analytics applications.
Data Engineers build the tools and platforms to answer questions with data, using software engineering best practices, computer science fundamentals, core database principles, and recent advances in distributed systems.
“Data engineers are specialized software engineers that enable others to answer questions on datasets, within latency constraints” - Nathan Marz, Inventor of Apache Storm and the Lambda Architecture
Data Engineering processes and components
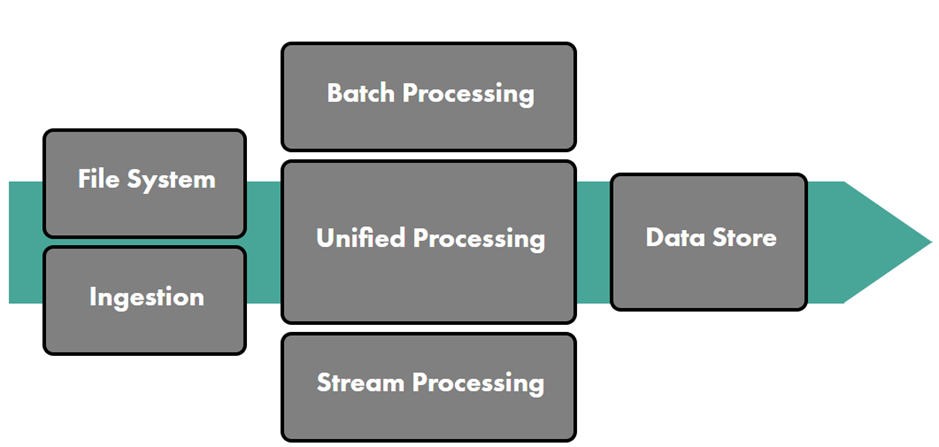
File Systems: Distributed file systems offer many of the features of local file systems, but with added protection from storing data redundantly. File systems are often used as a source of truth for later transformations on the data. They are optimized for durable, persistent storage of raw and unstructured data, rather than the quick access and queries that databases provide.
Ingestion: Ingestion is the process of collecting data from real-time and static sources. Many tools are available for ensuring that data can be collected reliably by a distributed cluster of machines, even when the machines or network are imperfect.
Batch processing: Batch processing is the general process of computing information from vast amounts of “bounded” data by using a distributed cluster of machines, typically over the course of several minutes or hours. The MapReduce paradigm for parallel programming has been the standard, but there are other alternatives developing.
Stream processing: Unlike batch processing, streaming technologies can process real-time data and events in milliseconds, allowing computations that would be too complicated with messaging queues alone. There are several solutions that support different levels of throughput and guarantees that the data processed, even when machines or the network fails.
Data Storage: Once data has been processed by the streaming or batch computations, it needs to be stored in a way that can be quickly accessed by the end user or data scientist. While file systems are designed to store data durably, databases organize data in a way that minimizes unnecessary disk seeks and network transfers to provide the quickest response to queries. There are hundreds of options for databases and finding the correct one that organizes data correctly for a specific use case is one of the most important decisions for data engineers.
Data Engineering Ecosystem
Lambda Architecture
When processing large amounts of semi-structured data, there is always a delay between the point when data is collected and its availability in dashboards.
Often the delay results from the need to validate or at least identify coarse data.
In some cases, however, being able to react immediately to new data is more important than being 100 percent certain of the data’s validity.
Stream or real-time processing, the processing of a constant flux of data, in real time, is possible with a Lambda Architecture solution.
A Lambda Architecture approach mixes both batch and stream (real-time) data processing.
It is divided into three processing layers:
- batch layer
- serving layer
- speed layer
All new data is sent both to the batch layer and to the speed layer.
Batch layer
In the batch layer, new data is appended to the master data set, a set of files that contains information that is not derived from any other information.
It is an immutable, append-only set of data.
The batch layer precomputes query functions continuously.
The results of the batch layer are called batch views.
Serving layer
The Serving layer indexes the batch views produced by the batch layer. Basically, the serving layer is a scalable database that swaps in new batch views as they become available.
Due to the latency of the batch layer, the results from the serving layer are always out-of-date by a few hours.
Speed layer
The Speed Layer compensates for the high latency of updates to the serving layer.
It process data that has not been processed in the last batch of the batch layer.
This layer produces the realtime views that are always up-to-date; it stores them in databases for both read and write operations.
The speed layer is more complex than the batch layer due to the fact that the real-time views are continuously discarded as data makes its way through the batch and serving layers.
Queries are resolved by merging the batch and real-time views.
Because the batch views are always recomputed completely, it is therefore possible to adjust the granularity of the data in function of its age.
Another benefit of recomputing data from scratch is that if the batch or real-time views are corrupt, as the main data set is append only, it is easy to restart and recover from the unstable state.
The end user can always query the latest version of the data, which is available from the speed layer.
The downside to traditional Lambda Architecture is that you must maintain the code required to produce the query result in two, complex, distributed systems.
Unified processing
As the most recent generation of distributed computing frameworks have matured, they have also begun to reimagine the data pipelines more fundamentally. Many technologies now take the view that batch processing problems are simply a subset of stream processing problem. These tools in particular have created abstraction for operators that can be run on batch and streaming data sets as well as the required underlying architecture.