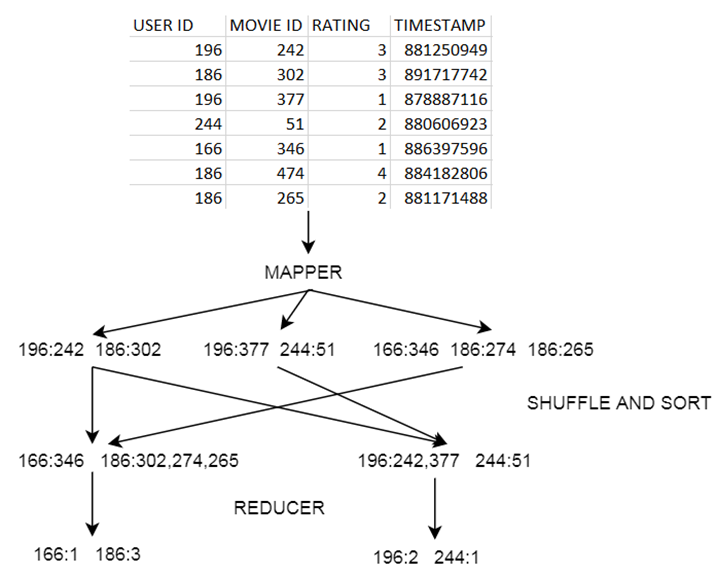
MapReduce Example
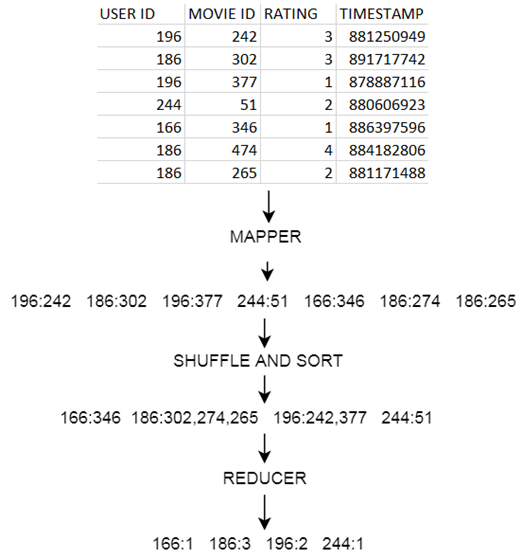
Let’s use the MovieLens dataset as an example and find out how many movies did each user rated.

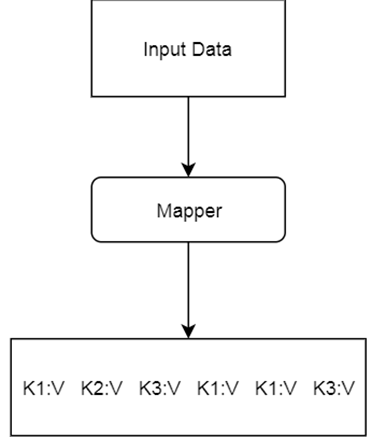
The MAPPER converts raw source data into key/value pairs
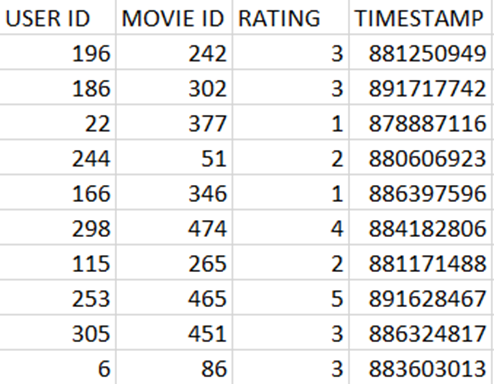
This is how the MovieLens u.data looks like:
- Map users to movies they watched:

- Extract and organize data we care about.
- The less data we put on the cluster, the better.
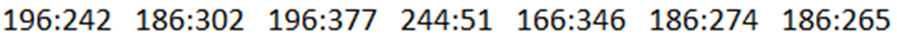
- MapReduce sorts and groups the mapped data (“Shuffle and Sort”)
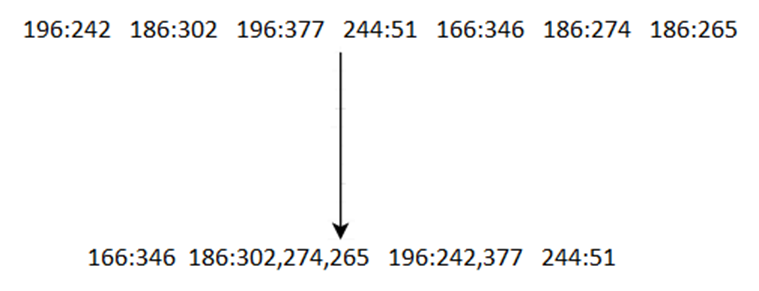
- The REDUCER Processes each key’s values
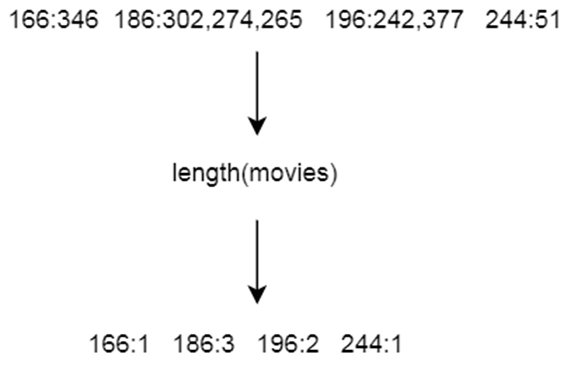
- To summarize:
- Example on a cluster: