HDFS
Why HDFS?
Big Data usually outgrows the storage capacity of a single physical machine. It becomes necessary to partition the data across a network of machines, or cluster. Hence we need a file system that manage the storage across a network of machines. Such file systems are called distributed file systems.
Distributed file systems are more complex than regular disk file systems, since they are network based. One of the biggest challenges is to tolerate node failure without suffering data loss.
Hadoop comes with a distributed file system called HDFS, which stands for Hadoop Distributed File system.
HDFS Design
HDFS was inspired by the GoogleFS whitepaper released in 2003. Google outlined how they were storing the large amount of data captured by their web crawlers.
There are several key design principles which require that the file system
is scalable.
is fault tolerant.
uses commodity hardware.
supports high concurrency.
HDFS appears to a client as if it is one system, but the underlying data is located in multiple different locations. HDFS gives a global view of your cluster. HDFS is immutable, meaning it has the inability to update data after it is committed to the file system.
HDFS Drawbacks
HDFS does not work well for some applications, including:
Low-latency data access: Applications that require low-latency access to data, in the tens of milliseconds range, will not work well with HDFS.
Lots of small files: Because filesystem metadata is hold in memory, the limit to the number of files in a filesystem is governed by the amount of memory available. Each file, directory, and block takes about 150 bytes metadata in memory, e.g. one million files, each taking one block, would need at least 300 MB of memory.
Multiple writers: Files in HDFS may be written to by a single writer. Writes are always made at the end of the file, in append-only fashion. There is no support for multiple writers or for modifications at arbitrary offsets in the file.
HDFS Blocks
Like in a local filesystem (e.g. NTFS, EXT4), files in HDFS are broken into block-sized chunks, which are stored as independent units.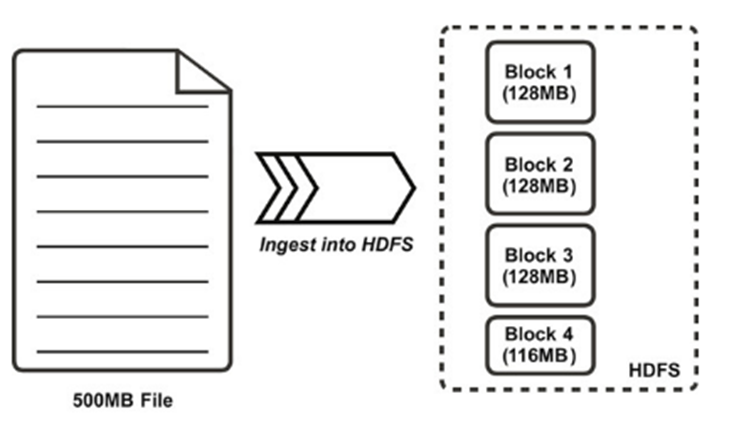
HDFS blocks are larger (128 MB by default) than single disk blocks to minimize the cost of seeks.
If a cluster contains more than one node, blocks are distributed among slave nodes.
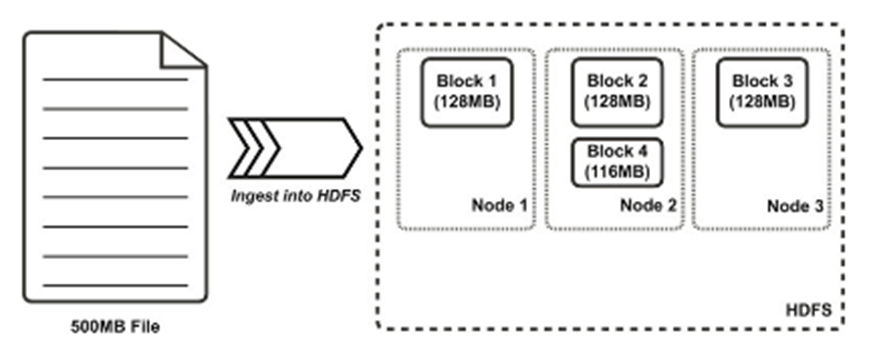
Having a block abstraction for a distributed filesystem brings several benefits.
- There is nothing that requires the blocks from a file to be stored on the same disk, so a file can be larger than any single disk in the network.
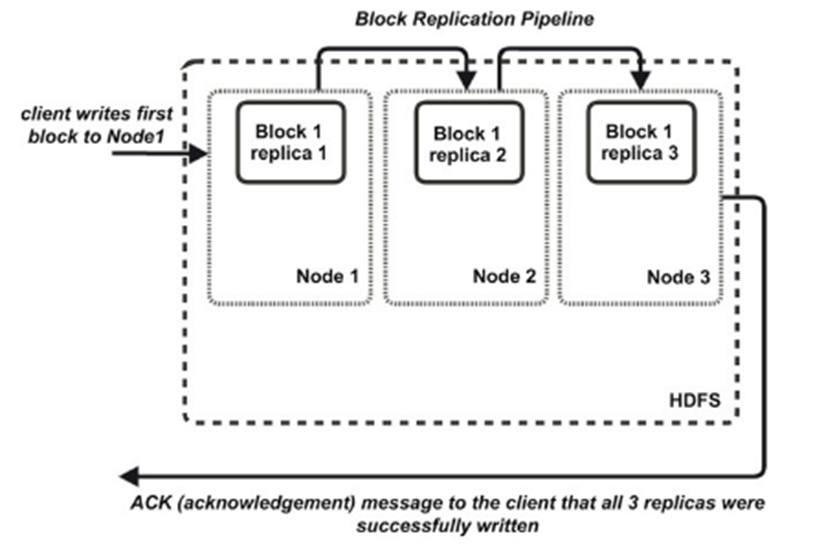
- Blocks fit well with replication for providing fault tolerance and availability. Each block is replicated to a small number of physically separate machines.
- By default HDFS replicates a block to 3 nodes.
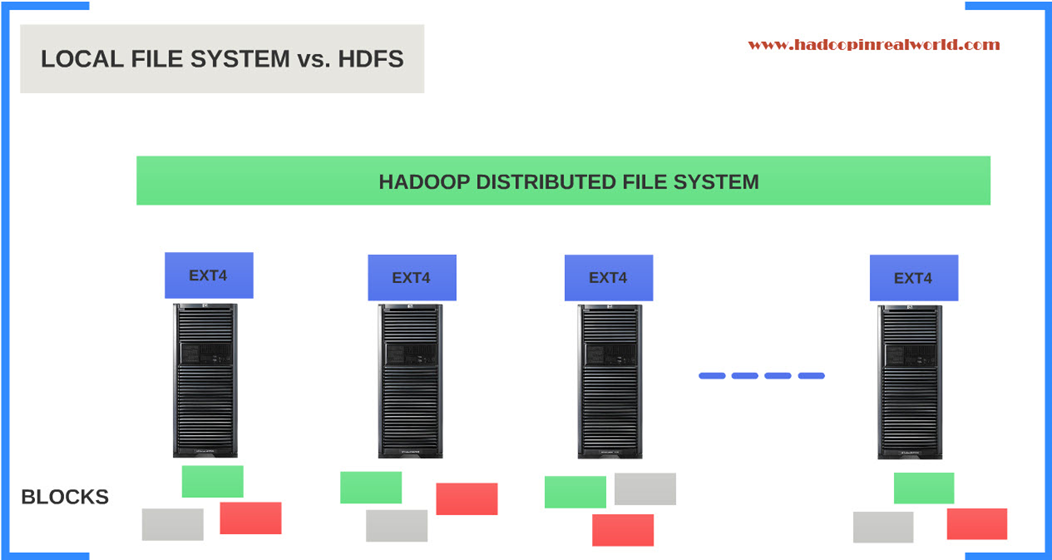
HDFS vs Local file system
HDFS by no means is a replacement for the local file system. The operating system still rely on the local file system. HDFS should still go through the local file system (typically ext4) to save the blocks in the storage. HDFS is spread across all the nodes in the cluster and it has a distributed view of the cluster. The local file system does not have a distributed view and only has a local view.
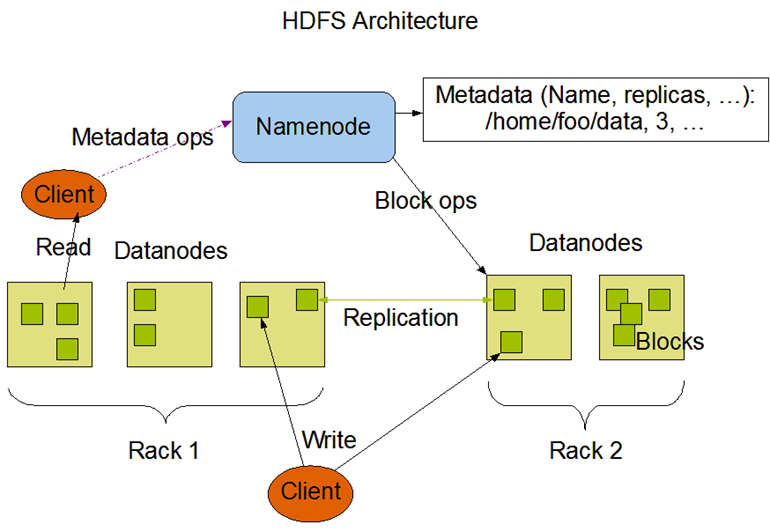
Namenode
The NameNode’s most important function is management of the filesystem’s metadata.
HDFS metadata is the filesystem catalog, which contains all of the directory and file objects and their related properties and attributes.
NameNode’s in-memory representation of the metadata includes the locations of the blocks which comprise files in HDFS.
- This is the only stateful representation of the relationship between files and blocks in HDFS.
- If the machine hosting the NameNode fails all the files on the filesystem would be lost.
- The NameNode must be resilient to failure.
Namenode Metadata
The NameNode’s metadata is perhaps the single most critical component in the HDFS architecture.
The metadata persists in resident memory on the NameNode to facilitate fast lookup operations for clients.
Common misconception: data does not flow through the NameNode.
The NameNode simply uses its metadata to direct clients where to read and write data.
Think of the metadata as a giant lookup table, which includes HDFS blocks, the HDFS object (file or directory) they are associated with, and their sequence in the file.

Datanodes
DataNodes are responsible for:
- storing and retrieving blocks when they are told to (by clients or the NameNode).
- participating in the block replication pipeline.
- managing local volumes and storage.
- providing block reports to the NameNode.
DataNodes store and manage physical HDFS blocks only, without having any knowledge of how these blocks are related to files and directories in the HDFS filesystem.
HDFS Architecture