Apache Spark
Apache Spark is an open source cluster computing framework for large-scale data processing project that was started in 2009 at the University of California, Berkeley.
Spark was founded as an alternative to using traditional MapReduce on Hadoop, which was deemed to be unsuited for interactive queries or real-time, low-latency applications. A major disadvantage of Hadoop’s MapReduce implementation was its persistence of intermediate data to disk between the Map and Reduce processing phases.
Spark is closely integrated with Hadoop: it can run on YARN and works with Hadoop file formats and storage backends like HDFS.
Spark has more than 400 individual contributors and committers from companies such as Facebook, Yahoo!, Intel, Netflix, Databricks, and others.
Spark maximizes the use of memory across multiple machines, improving overall performance by orders of magnitude.
Spark’s reuse of these in-memory structures makes it well-suited to iterative, machine learning operations, as well as interactive queries.
Spark Architecture
A Spark application contains several components, all of which exist whether Spark is running on a single machine or across a cluster of hundreds or thousands of nodes.
The components of a Spark application are:
- The Driver Program and the SparkContext Object.
- The Cluster Manager.
- The Executor(s), which run on slave nodes or workers.
Driver Program
The life of a Spark application starts and finishes with the Driver Program or Spark driver. The Spark driver is the process clients use to submit applications in Spark.
The driver is also responsible for planning and coordinating the execution of the Spark program and returning status and/or results (data) to the client.
The Spark driver is responsible for creating the SparkContext object. The SparkContext is instantiated at the beginning of a Spark application (including the interactive shells) and is used for the entirety of the program.
Cluster Manager
To run on a cluster, the SparkContext can connect to several types of cluster managers (Spark’s standalone cluster manager, Mesos or YARN), which allocate resources across applications.
Spark is agnostic to the underlying cluster manager. As long as it can acquire executor processes, and these communicate with each other, it is relatively easy to run it even on a cluster manager that also supports other applications (e.g. Mesos/YARN).
Executors
Spark executors are the host processes on which tasks from a Spark DAG are run. Executors reserve CPU and memory resources on slave nodes or workers in a Spark cluster. Executors are dedicated to a specific Spark application and terminated when the application completes. A Spark executor can run hundreds or thousands of tasks within a Spark program.
A worker node or slave node, which hosts the executor process, has a finite or fixed number of executors that can be allocated at any point in time.
Executors store output data from tasks in memory or on disk.
Workers and executors are only aware of the tasks allocated to them, whereas the driver is responsible for understanding the complete set of tasks and their respective dependencies that comprise an application.
Spark Architecture overview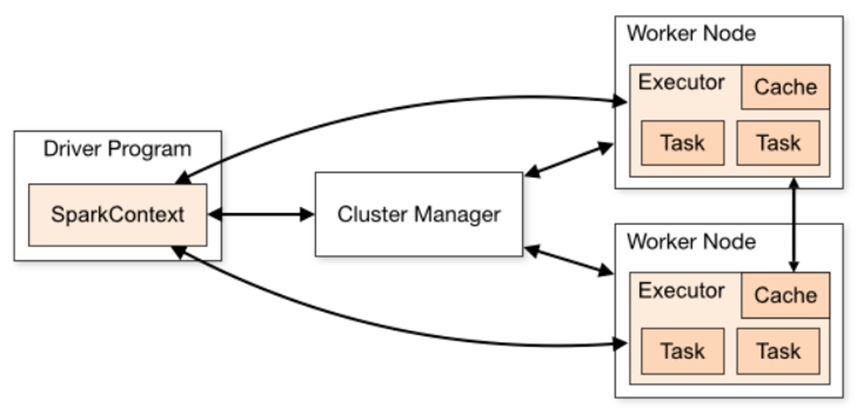
Data Interfaces
There are several key Data interfaces in Spark:
- RDD (Resilient Distributed Dataset): Apache Spark’s first abstraction and most fundamental data object used in Spark programming.
- DataFrame: Collection of distributed Row types. Provide a flexible interface and are similar in concept to the DataFrames in Python (Pandas) or R.
- Dataset: Apache Spark’s newest distributed collection and can be considered a combination of DataFrames and RDDs. Provides the typed interface that is available in RDDs while providing a lot of the conveniences of DataFrames.
Transformations and Actions
There are two types of operations that can be performed with Spark: transformations and actions.
- In Spark, core data structures are immutable. Transformations are operations performed against data interfaces (RDD, DataFrame, Dataset) that result in the creation of new data interfaces.
- In contrast to transformations, which return new objects, actions produce output such as data from a data interface return to a driver program, or save the content to a file system (local, HDFS, S3, or other).
Lazy Evaluation
Spark uses lazy evaluation (also called lazy execution) in processing Spark programs. Lazy evaluation defers processing until an action is called (therefore when output is required). After an action such as count() or saveAsTextFile() is requested, a DAG is created along with logical and physical execution plans. These are then orchestrated and managed across executors by the driver.
This lazy evaluation allows Spark to combine operations where possible, thereby reducing processing stages and minimizing the amount of data transferred between Spark executors, a process called the shuffle.
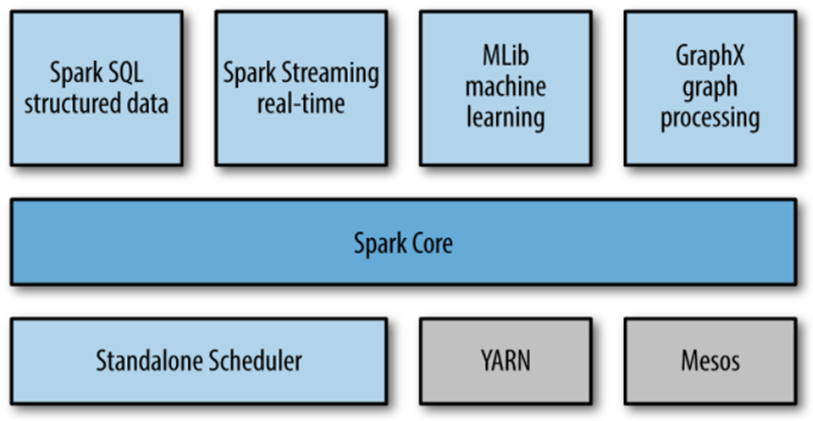
Spark Stack
The Spark project contains multiple closely integrated components. The core engine of Spark powers multiple higher-level components specialized for various workloads, such as SQL or machine learning.
These components are designed to interoperate closely, letting users combine them like libraries in a software project.
Spark Core contains the basic functionality of Spark, including components for task scheduling, memory management, fault recovery, interacting with storage systems, and more. Spark Core is also home to the API that defines resilient distributed datasets (RDDs).
Databricks
Databricks is a company founded by the creators of Apache Spark, that aims to help clients with cloud-based big data processing using Spark. Databricks grew out of the AMPLab project at University of California, Berkeley that was involved in making Apache Spark.
Databricks develops a web-based platform for working with Spark, that provides automated cluster management and IPython-style notebooks.