Transformations and Actions
Spark allows two distinct kinds of operations by the user. There are transformations and there are actions.
Transformations
Transformations are operations that will not be completed at the time you write and execute the code in a cell - they will only get executed once you have called an action. An example of a transformation might be to convert an integer into a float or to filter a set of values.
Actions
Actions are commands that are computed by Spark right at the time of their execution. They consist of running all of the previous transformations in order to get back an actual result. An action is composed of one or more jobs which consists of tasks that will be executed by the workers in parallel where possible.
# An example of RDD created from a list
numList = [1,2,3,4,5]
firstRDD = sc.parallelize(numList)
# An example of a transformation
# Multiply the values by 2
secondRDD = firstRDD.map(lambda x: x*2)
# An example of an action
secondRDD.collect()
It gives a simple way to optimize the entire pipeline of computations as opposed to the individual pieces. This makes it exceptionally fast for certain types of computation because it can perform all relevant computations at once. Technically speaking, Spark pipelines this computation which we can see in the image below. This means that certain computations can all be performed at once (like a map and a filter) rather than having to do one operation for all pieces of data and then the following operation.
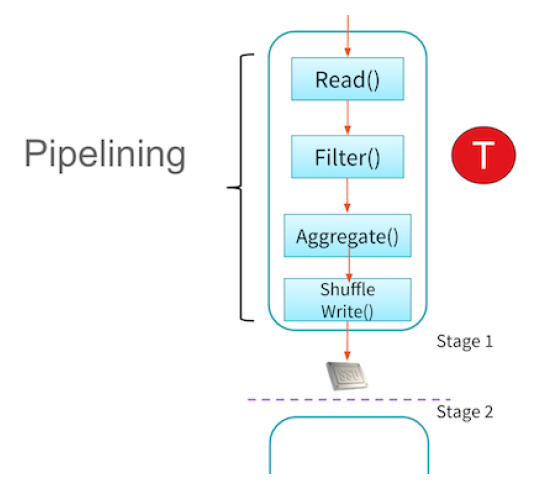
Transformations are lazy in order to build up the
entire flow of data from start to finish required by the user. Any calculation can be recomputed from the very
source data allowing Apache Spark to handle any failures that occur along the way,
and successfully handle stragglers. With each transformation Apache Spark creates a plan for how it will
perform this work.
To get a sense for what this plan consists of, run the following code in a cell (we will explain this code later):
wordsList = ['cat', 'elephant', 'rat', 'rat', 'cat']
wordsRDD = sc.parallelize(wordsList)
wordCountsCollected = (wordsRDD
.map(lambda x: (x,1))
.reduceByKey(lambda a,b: a+b)
.collect())
Click the little arrow next to where it says (1) Spark Jobs after that cell finishes executing and then click the View link. This brings up the Apache Spark Web UI right inside of your notebook. This can also be accessed from the cluster attach button at the top of this notebook. In the Spark UI, you should see something that includes a diagram similar to this:
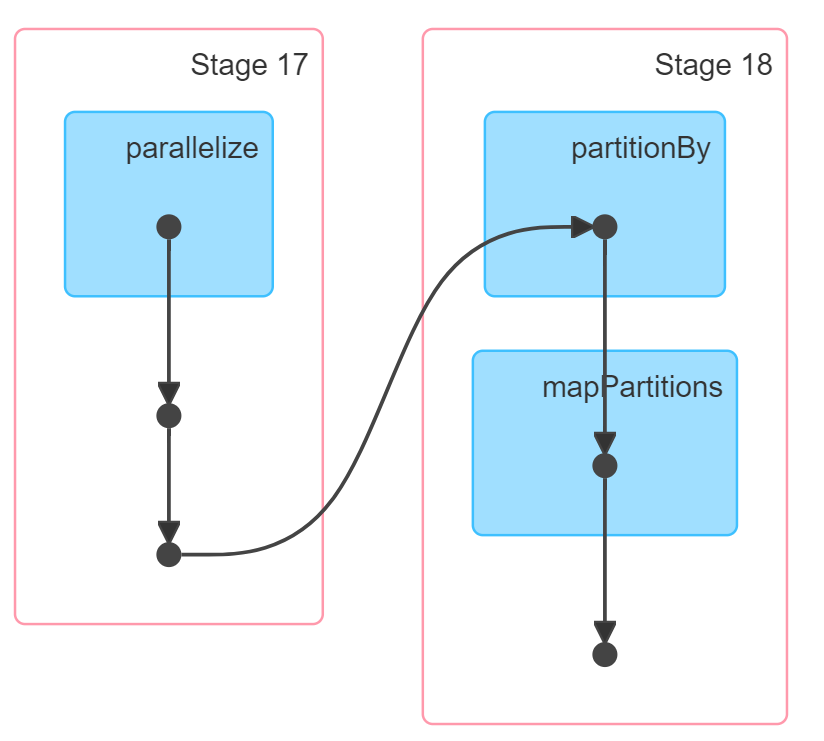 This is a Directed Acyclic Graphs (DAG)s of all the computations that have to be performed in order to get to that result. Again, this DAG is generated because transformations are lazy - while generating this series of steps Spark will optimize lots of things along the way and will even generate code to do so.
This is a Directed Acyclic Graphs (DAG)s of all the computations that have to be performed in order to get to that result. Again, this DAG is generated because transformations are lazy - while generating this series of steps Spark will optimize lots of things along the way and will even generate code to do so.