Sqoop
In the previous lesson we learn about different type of storage repositories outside of HDFS.
Often, valuable data in an organization is stored in structured data stores such as relational database management systems (RDBMSs).
Apache Sqoop(which is a portmanteau for “sql-to-hadoop”) is an open source tool that allows users to extract data from a structured data store into Hadoop for further processing. This processing can be done with MapReduce programs or other higher-level tools such as Hive, Pig or Spark.
Sqoop can automatically create Hive tables from imported data from a RDBMS (Relational Database Management System) table.
Sqoop can also be used to send data from Hadoop to a relational database, useful for sending results processed in Hadoop to an operational transaction processing system.
Sqoop includes tools for the following operations:
- Listing databases and tables on a database system
- Importing a single table from a database system, including specifying which columns to import and specifying which rows to import using a WHERE clause
- Importing data from one or more tables using a SELECT statement
- Incremental imports from a table on a database system (importing only what has changed since a known previous state)
- Exporting of data from HDFS to a table on a remote database system
Sqoop Connectors
Sqoop has an extension framework that makes it possible to import data from — and export data to — any external storage system that has bulk data transfer capabilities.
A Sqoop connector is a modular component that uses this framework to enable Sqoop imports and exports.
Sqoop ships with connectors for working with a range of popular databases, including MySQL, PostgreSQL, Oracle, SQL Server, DB2, and Netezza.
As well as the built-in Sqoop connectors, various third-party connectors are available for data stores, ranging from enterprise data warehouses (such as Teradata) to NoSQL stores (such as Couchbase).
There is also a generic JDBC (Java Database Connectivity) connector for connecting to any database that supports Java’s JDBC protocol.
# movielens DB must be created in MySQL using movielens.sql
sqoop import \
--connect jdbc:mysql://172.31.26.67:3306/movielens \
--table genres \
--username ubuntu \
--password ubuntu \
--target-dir /user/ubuntu/sqoop/movielens/genres
sqoop import \
--connect jdbc:mysql://172.31.26.67:3306/movielens \
--table genres
-m 2 \
--username ubuntu \
--password ubuntu \
--target-dir /user/ubuntu/sqoop/movielens/genres2
Sqoop is capable of importing into a few different file formats.
By default, Sqoop will generate comma-delimited text files for our imported data.Delimiters can be specified explicitly.
Sqoop also supports SequenceFiles, Avro datafiles, and Parquet files.
sqoop import \
--connect jdbc:mysql://172.31.26.67:3306/movielens \
--table genres \
-m 1 \
--username ubuntu \
--password ubuntu \
--target-dir /user/ubuntu/sqoop/movielens/genres3 \
--fields-terminated-by '\t' \
--enclosed-by '"'
sqoop import \
--connect jdbc:mysql://172.31.26.67:3306/movielens \
--table genres \
--columns "id, name" \
--where "id > 5" \
-m 1 \
--username ubuntu \
--password ubuntu \
--target-dir /user/ubuntu/sqoop/movielens/genres4
We can specify many more options when importing a Database using Sqoop, such as:
- --fields-terminated-by
- --lines-terminated-by
- --null-non-string
- --null-string "NA"
Create a new table in MySQL using the following steps:
mysql -u root -p
# Create table in movielens
use movielens;
CREATE TABLE users_replica AS select u.id, u.age, u.gender,
u.occupation_id, o.name as occupation
from users u LEFT JOIN occupations o
ON u.occupation_id = o.id;
select * from users_replica limit 10;
# Alter table
alter table users_replica add primary key (id);
alter table users_replica add column (salary int, generation varchar(100));
update users_replica set salary = 120000 where occupation = 'Lawyer';
update users_replica set salary = 100000 where occupation = 'Engineer';
update users_replica set salary = 80000 where occupation = 'Programmer';
update users_replica set salary = 0 where occupation = 'Student';
update users_replica set generation = 'Millenial' where age<35;
update users_replica set generation = 'Boomer' where age>55;
exit;
Then run the following Sqoop job:
sqoop import \
--connect jdbc:mysql://172.31.26.67:3306/movielens \
--username ubuntu \
--password ubuntu \
--table users_replica \
--target-dir /user/ubuntu/sqoop/movielens/users \
--fields-terminated-by '|' \
--lines-terminated-by '\n' \
-m 3 \
--where "id between 1 and 300" \
--null-non-string -1 \
--null-string "NA"
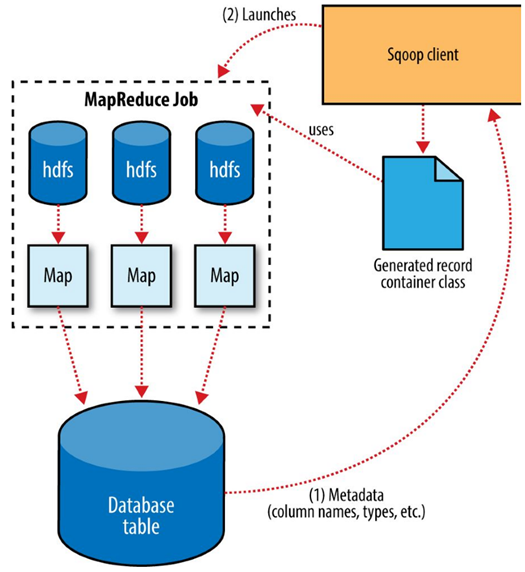
How Sqoop works
Sqoop is an abstraction for MapReduce, meaning it takes a command, such as a request to import a table from an RDBMS into HDFS, and implements this using a MapReduce processing routine. Specifically, Sqoop implements a Map-only MapReduce process.
Sqoop performs the following steps to complete an import operation:
- Connect to the database system using JDBC or a customer connector.
- Examine the table to be imported.
- Create a Java class to represent the structure (schema) for the specified table. This class can then be reused for future import operations.
- Execute a Map-only MapReduce job with a specified number of tasks (mappers) to connect to the database system and import data from the specified table in parallel.
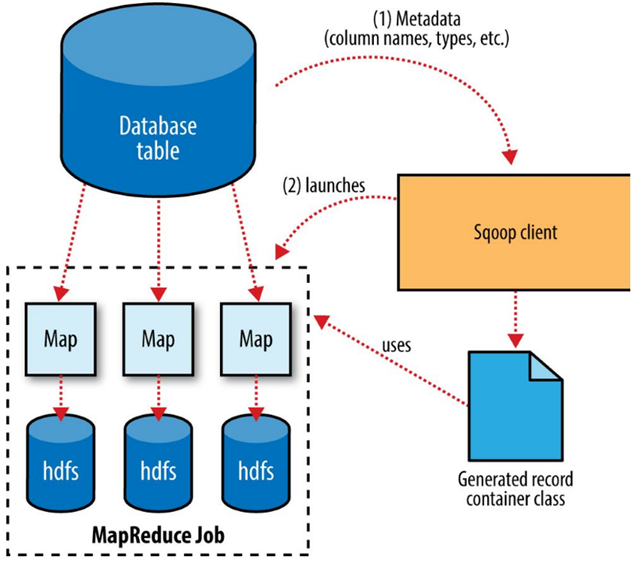
When importing data to HDFS, it is important that you ensure access to a consistent snapshot of the source data.
We need to ensure that any processes that update existing rows of a table are disabled during the import.
Imported Data and Hive
Using a system such as Hive to handle relational operations can dramatically ease the development of the analytic pipeline.
Sqoop can generate a Hive table based on a table from an existing relational data source.
## Create database movielens in Hive
#3 steps import into Hive:
# 1. import data to HDFS
sqoop import \
--connect jdbc:mysql://172.31.43.67:3306/movielens \
--table genres -m 1 \
--username ubuntu \
--password ubuntu \
--target-dir /user/ubuntu/sqoop/movielens/genres
# 2. create table in Hive
sqoop create-hive-table \
--connect jdbc:mysql://172.31.26.67:3306/movielens \
--table genres \
--hive-table movielens.genres \
--username ubuntu \
--password ubuntu \
--fields-terminated-by ','
# 3. import data from HDFS to Hive
#Run commands in Hive:
Hive
hive> show databases;
hive> use movielens;
hive> show tables;
hive> select * from genres;
hive> LOAD DATA INPATH "/user/ubuntu/sqoop/movielens/genres" OVERWRITE INTO TABLE genres;
hive> select * from genres;
hive> exit;
#run commands in Terminal
hadoop fs -ls /user/ubuntu/sqoop/movielens/genres
hadoop fs -ls /user/hive/warehouse/movielens.db/genres
hadoop fs -cat /user/hive/warehouse/movielens.db/genres/part-m-00000
# Direct import into Hive
sqoop import \
--connect jdbc:mysql://172.31.26.67:3306/movielens \
--table genres -m 1 \
--hive-import \
--hive-overwrite \
--hive-table movielens.genres2 \
--username ubuntu \
--password ubuntu \
--fields-terminated-by ','
#run commands in Terminal
hadoop fs -ls /user/hive/warehouse/movielens.db/genres
hadoop fs -cat /user/hive/warehouse/movielens.db/genres/part-m-00000
Sqoop Export
In Sqoop, an import refers to the movement of data from a database system into HDFS. By contrast, an export uses HDFS as the source of data and a remote database as the destination. We can, for example, export the results of an analysis to a database for consumption by other tools.
Before exporting a table from HDFS to a database, we must prepare the database to receive the data by creating the target table. Although Sqoop can infer which Java types are appropriate to hold SQL data types, this translation does not work in both directions. You must determine which types are most appropriate.
When reading the tables directly from files, we need to tell Sqoop which delimiters to use. Sqoop assumes records are newline-delimited by default, but needs to be told about the field delimiters.
# Create table in MySQL
mysql -u ubuntu -p
mysql> use movielens;
mysql> create table genres_export (id INT, name VARCHAR(255));
mysql> exit;
# Export data from hive warehouse to mysql
sqoop export \
--connect jdbc:mysql://172.31.26.67:3306/movielens -m 1 \
--table genres_export \
--export-dir /user/hive/warehouse/movielens.db/genres \
--username ubuntu \
--password ubuntu
# Check the exported table in mysql
mysql -u root -p
use movielens;
show tables;
select * from enres_export limit 10;
The Sqoop performs exports is very similar in nature to how Sqoop performs imports. Before performing the export, Sqoop picks a strategy based on the database connect string.
Sqoop then generates a Java class based on the target table definition. This generated class has the ability to parse records from text files and insert values of the appropriate types into a table
A MapReduce job is then launched that reads the source datafiles from HDFS, parses the records using the generated class, and executes the chosen export strategy.